
SensAI Predict assigns Labels to Issues based on the data that you’ve provided to the Model in the form of a dataset. The performance of the Model and the accuracy of your Labels depends on the following factors:
- The quality of the dataset you provide (containing the user’s first messages and Labels)
- The amount of data provided for SensAI Predict to learn from
- The accuracy of the labeling in your datasets: if more than one person helped to compile the information in a given dataset, it should be double checked for consistency in the Labels used and the messages they are applied to
- Feedback provided by your Agents on Issues labeled by SensAI Predict – your Model will improve over time based on this feedback
To maximize the accuracy of your Labels, it is essential that you review the following questions and best practices for effectively planning your Labels and preparing your data.
Planning Your Labels
Your Labels should be planned based on how you need to classify Issues for prioritization and assignment via your existing workflow. When deciding what types of Labels to create and how many to have, consider the following:
Do you want to treat similar Issues from different support channels differently? For instance, you may want to route billing-related Issues from web contact us form to one queue, and shipping-related Issues from live chat to a different, higher-priority queue. Figuring out how you want to triage and route Issues from different support channels will help you decide if you want to create one domain-level single model or multiple models.
How many different Agent Groups or Teams do you have, and how are they specialized? This may help you to decide which classifications will be the most actionable for each Group or Team.
How many Labels do you need, and what is the level of detail you want for these Labels? SensAI Predict works best for broad classifications that are distinctly different from one another. For example, you may want a set of classifications such as billing, shipping complaints, and VIP, but also need an additional level of detail for the billing category, such as credit_card_billing vs. paypal_billing. If you need this additional Label of detail, you will need to provide more data than if you only needed to have Labels for broad categories.
Are you currently using Custom Issue Fields or tags to classify Issues? If your current grouping of Issues via Custom Issue Fields or tags works well for your team, you may wish to simply reuse those existing categories for your Labels.
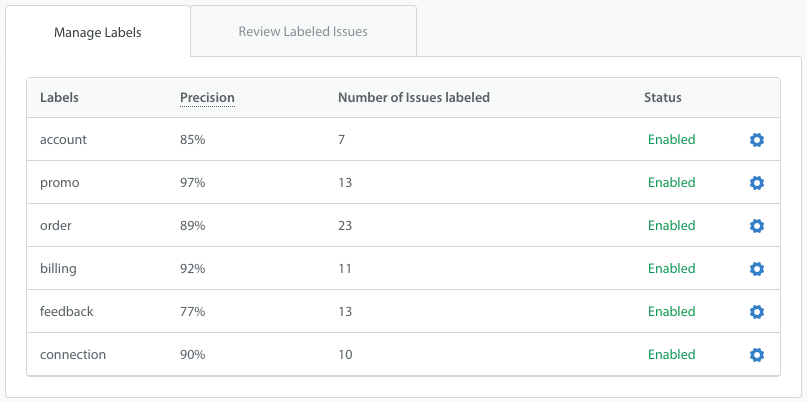
How many different languages do you need to support? Predict currently supports the following languages:
- Arabic
- Chinese (Simplified)
- Chinese (Traditional)
- Korean
- English
- French
- German
- Italian
- Japanese
- Portuguese
- Russian
- Spanish
- Turkish
- Indonesian
- Persian
- Dutch
- Ukrainian
- Polish
- Catalan
- Vietnamese
Creating Your Dataset
The dataset must be provided to the Model as a zip file that contains a CSV that consists of two columns: <label> and <user’s first message>, where is the category of the Issue.
To gather the data that you need for your dataset, filter for the relevant Issues using the drop-downs in the ‘Download Data from within Helpshift’ section of the ‘Prepare data’ page within Predict, then click the ‘Download’ button.
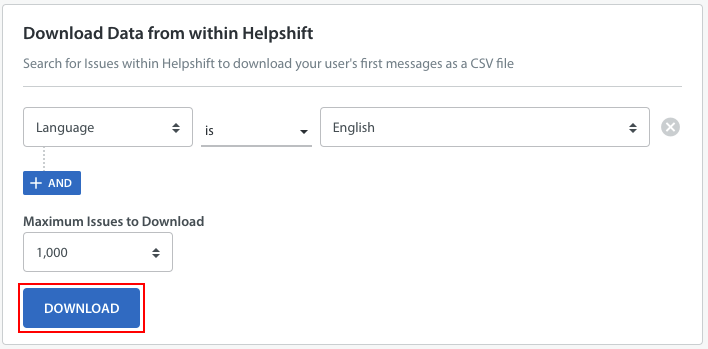
This will provide you with a file containing all of the user’s first messages in column B, with an empty ‘label’ Column A. Add the Labels that you have planned according to your workflow.

When preparing this file, please note the following:
- In order for the label to be parsed correctly, you must place two dollar signs before and after each label, so that it is written as $$Label$$
- Each line in the file should contain only one Issue/Label pair
- There is no limit on the number of lines you can provide in the file – however, there is a 25MB size limit for the file itself
- Remember that all Models are language-specific, which means you must create language-specific training datasets for each Model
Additionally, please note that we currently impose the following limits:
- A maximum of 100 Labels per Model
- A minimum of 500 Issues per individual Label in the Model
We recommend providing as much data to your Model as possible. This data can be sourced from over a large time frame, such as Issues from the past few weeks, months, or even years. However, if you do provide older Issues, it is important that you Label those Issues in a way that reflects your current workflow. This helps you avoid the Model learning classifications that are outdated.
Once your dataset is complete, you’ll be able to upload it in the ‘Upload Data’ area during the training phase.
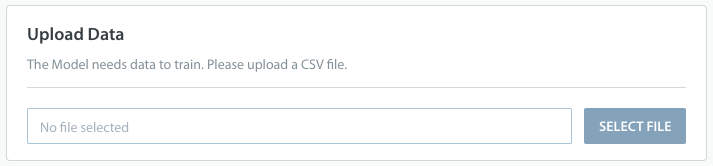
You can also download a sample CSV file from within the Predict area of your Helpshift Dashboard and populate that template with Issue information.
