
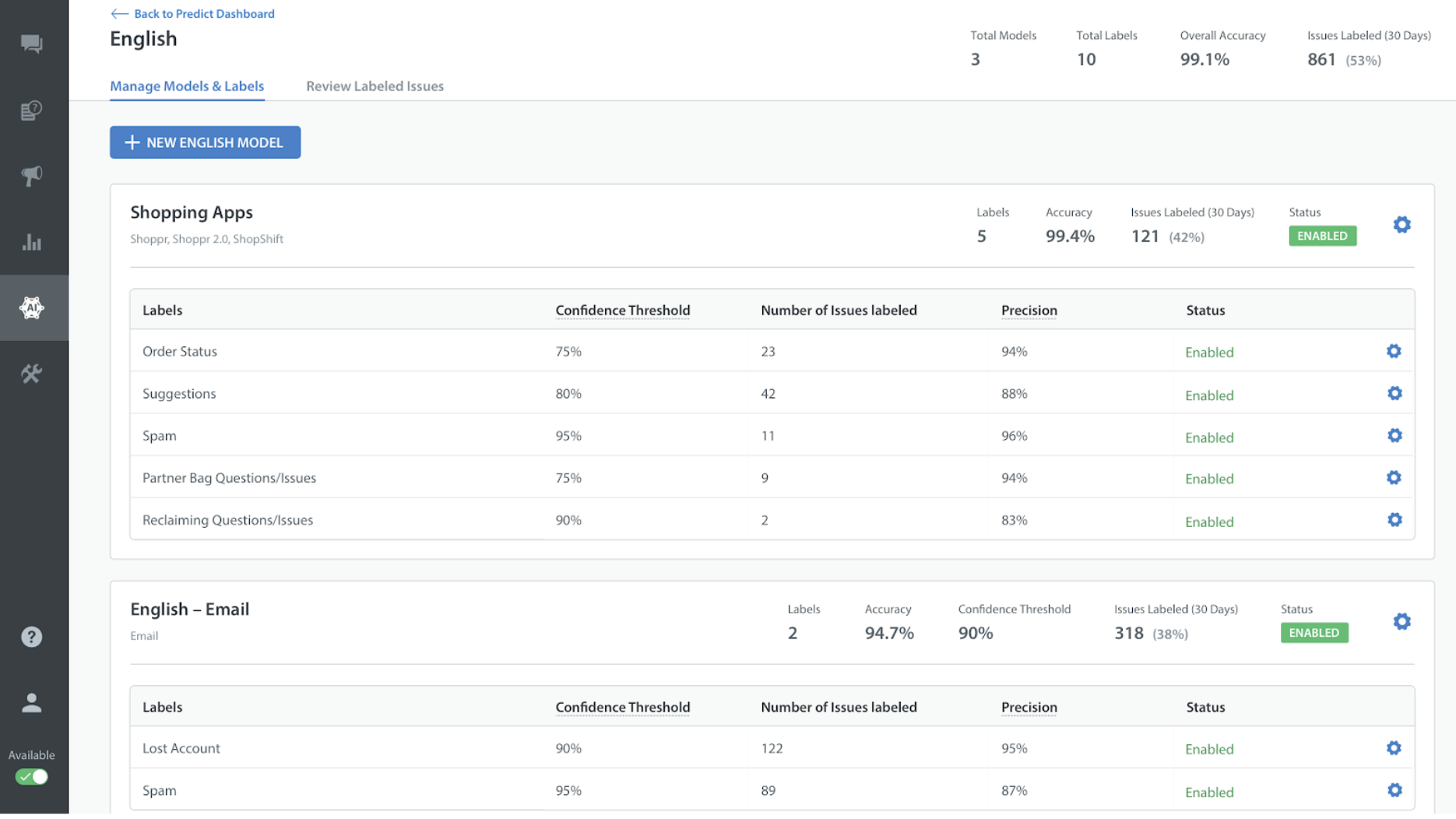
精度は、エージェントが予測されたラベルを誤りとしてマークしなかった回数の割合として計算されます。
精度はモデルのパフォーマンスを反映しています。精度計算には、モデル内のすべてのラベルが含まれます。
精度を測る公式は、(N-r) / (N)です。
N: ラベルが予測されたチケットの数
r: 予測されたラベルが別のラベルに変更されたり、誤りとしてマークされたチケットの数
精度は、エージェントが特定のラベルが予測された際に、それを誤りとしてマークしなかった割合として計算されます。精度はラベルごとに計算されるため、ラベルによって異なる場合があります。
精度を求める式は、(L-w) / Lです。
L: 特定のラベルが予測されたチケットの数
w: 特定の予測ラベルが別のラベルに変更された、または誤りとしてマークされたチケットの数
たとえば、2つのラベル「注文」と「請求」を持つ英語モデルがあるとします。このモデルで評価された1000件のチケットのうち、300件が「注文」として、500件が「請求」としてラベル付けされました。
「Orders」とラベル付けされた300件のチケットのうち、60件のラベルが貴社エージェントによって「Billing」に修正され、30件のラベルが誤りとしてマークされました。比較として、「Billing」ラベルの500件のうち、20件が貴社エージェントによって「Orders」に修正され、50件が誤りとしてマークされました。
これらのラベルに適用される精度の公式は以下の通りです。
- 注文の精度:(300 – 60 – 30)/(300)= 210 / 300 = 70%
- 請求の精度:(500 – 20 – 50)/(500)= 430 / 500 = 86%
このモデルの精度を測る公式は以下の通りです。
フィードバックに関するチケット:
- 注文数:(60 + 30)= 90
- 請求: (20 + 50) = 70
フィードバックに関するチケットの総数: 90 + 70 = 160
ラベル付けされたチケットの総数: 300 + 500 = 800
したがって、このモデルの精度は次のように計算されます。(800 – 160)/(800)= 80%
チケットが解決または終了された場合にのみ、精度と正確さを計算します。 そうすることで、チケットが未解決の間でもこれらのラベルを更新でき、チケットがクローズされるまで分析に新規指標が反映されることはありません。
精度と適合率の指標が高いほど、より良い結果が得られます。これらの指標が期待どおりでない場合は、より多くのデータをアップロードするか、そのモデルのラベルに関連付けられているデータを評価することを検討してください。詳細については、こちらをご覧ください:Predictモデルのデータ準備方法